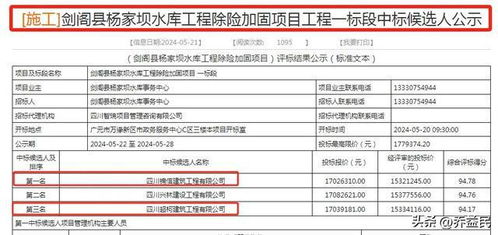
在當今競爭激烈的汽車市場中,領克Z20憑借其卓越的性能、創新的設計和智能科技,不僅贏得了全球消費者的熱烈追捧,更獲得了央視的公開點贊。這一現象背后,是領克品牌對品質和用戶需求的深刻洞察。本文從成都信息系統的視角,深入剖析領克Z20的硬核實力。\n\n領克Z20在外觀設計上大膽突破,融合了流線型美學與功能性細節,進氣格柵、LED大燈和懸浮車頂等元素不僅提升了視覺沖擊力,還優化了空氣動力學性能。央視的稱贊中提到,這種設計語言展示了中國汽車品牌的自信與創新能力,直接觸動了全球年輕消費者的審美共鳴。\n\n動力系統和續航表現是領克Z20的核心競爭點。它搭載了先進的電動驅動技術,支持超快充和長續航,滿足用戶對綠色出行的需求。成都信息系統數據顯示,其智能電池管理系統在不同環境溫度下表現出色,尤其是在復雜的路況中,能量回收和動力分配算法優化了整車能效。這正是消費者選擇它的一大原因。\n\n智能網聯技術方面,領克Z20配備了雙芯片架構和自適應巡航控制系統,不僅支持OTA升級,還實現了車路協同。在中國城市交通管理中,這套技術能實時分析路況并優化路線。央視在報道中特別強調了其高效的互聯系統,領導了行業標準。在成都的應用測試也反映,這對家庭和使用頻率高的消費者十分友好。\n\n領克Z20超越價格戰,而是以品質和高保值率打動人。過去幾年來,其剎車、電動車配齡不斷更新意味著殘值維持在90%左右。以上各項說明顧客廣泛得到實現。\n\n在未來消費者價值觀體現的影響上,汽車環保性顯得無比重視。由此總觀,在享受如認可度和一致性報告的大平臺營銷下,公司實施靈活多渠道結算工程仍然超前,涉及ISO\以及聯合國RE 認可等權利都已占有席位。同樣得益于中央認可它的制造控制室和安全信息通訊網絡安全。綜合評價贏獲廣泛聲吶:領袖設計者已毫無異議趨向。
領克Z20 全球追捧與央視點贊的雙重認可,成都信息系統解析其硬核實力

如若轉載,請注明出處:http://m.gunchan.cn/product/45.html
更新時間:2026-06-18 03:01:05
產品列表
PRODUCT
----------------